


Alibaba’s new AI sees, hears, talks in real time
Qwen2.5-Omni combines vision, speech, and language into one real-time model that’s small enough for edge devices.
Alibaba just dropped one of its most ambitious AI models yet — and it’s not trying to win by being the biggest. Instead, Qwen2.5-Omni, a new 7B-parameter multimodal model, is going for agility, versatility, and real-time performance across text, image, audio, and video.
Yes, it can see, hear, talk, and write. And yes, it's small enough to run on a consumer GPU or maybe even your phone. That’s a big deal.
The new model, available open-source under the Apache 2.0 license, is already live on Hugging Face, GitHub, and other platforms. It supports real-time interactions — including voice and video chats — and generates text and speech responses on the fly. If you’ve ever wished ChatGPT could talk back with less latency and more nuance, this might be your moment.
Thinker. Talker. Go.
At the heart of Qwen2.5-Omni is a new architecture Alibaba calls Thinker-Talker. It’s a dual-brain design where the “Thinker” handles perception and understanding — chewing through audio, video, and images — while the “Talker” turns those thoughts into fluent, streaming speech or text.
It’s built for end-to-end multimodal interaction, meaning it doesn't need to convert voice to text before understanding or thinking. It processes it all natively and in parallel.
To handle time-sensitive media like video and audio, Alibaba also introduced TMRoPE, a new way of syncing time across modalities. That helps it do things like lip-synced responses or answer questions about moving images more accurately.
It’s Tiny — But Mighty
What’s surprising is how much Qwen2.5-Omni packs into just 7 billion parameters — small by current LLM standards. For context, Meta’s LLaMA 3 is expected to top 140B. But Alibaba’s model is built to run on smaller machines without sacrificing too much capability.
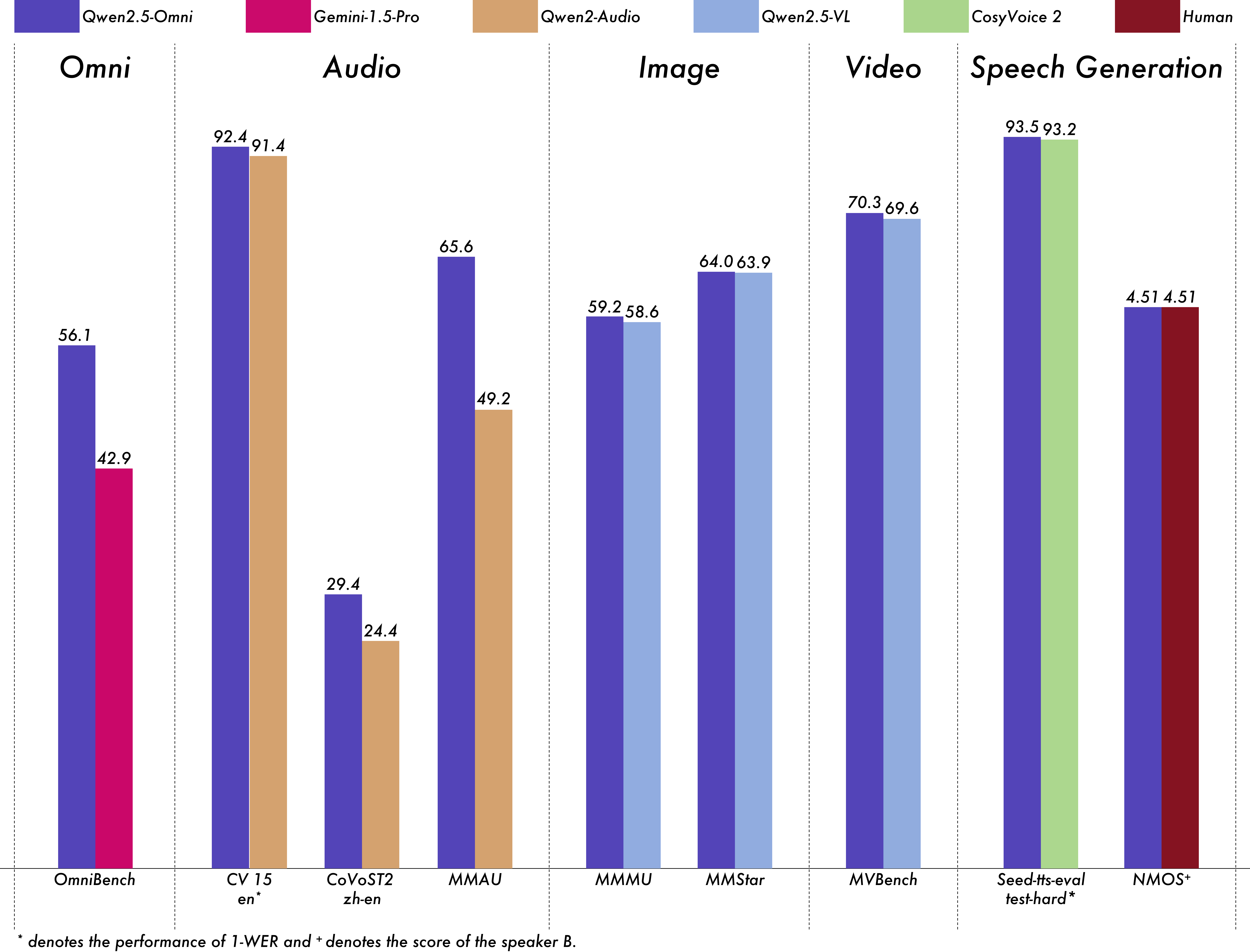
And the performance numbers? Solid. Qwen2.5-Omni beats out Alibaba’s own audio model (Qwen2-Audio), holds its own against its visual model (Qwen2.5-VL), and even competes with closed-source heavyweights like Gemini 1.5 Pro in multimodal reasoning.
Benchmarks show it excels in speech recognition (Common Voice), translation (CoVoST2), and even tough video understanding tests like MVBench. It’s especially good at real-time speech generation — which is tricky for smaller models.
Reactions: “It Just Works”
Keep reading with a 7-day free trial
Subscribe to China Innovation Watch to keep reading this post and get 7 days of free access to the full post archives.